CtrlK
See also: ChatGPT and ChatGPT Plugins GitHub
The ChatGPT Retrieval Plugin is a powerful addition to OpenAI's ChatGPT, enabling the AI to access and utilize data stored in a vector database. This capability not only enhances ChatGPT's performance by providing access to customized data but also addresses its long-standing limitation of lacking long-term memory. The plugin is part of the broader ChatGPT plugins ecosystem, which allows ChatGPT to interact with various apps and services, transforming it from a conversation tool to an AI capable of taking actions in the real world.
Recently, OpenAI introduced plugins for ChatGPT, which have significantly expanded the chatbot's capabilities. These plugins act as a bridge between the chatbot and a range of third-party resources, enabling it to leverage these resources to perform tasks based on user conversations. The Retrieval Plugin, specifically, has the potential to be widely used, as it allows users to create customized versions of ChatGPT tailored to their own data.
With the integration of plugins, ChatGPT can now perform various tasks such as ordering groceries, booking restaurants, and organizing vacations by utilizing services like Instacart, OpenTable, and Expedia. Moreover, the Zapier plugin allows ChatGPT to connect with thousands of other applications, from Google Sheets to Salesforce, thus broadening its reach.
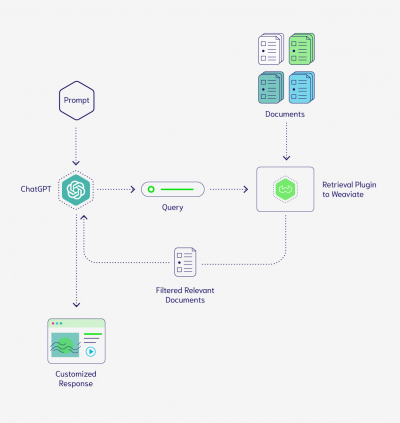
The ChatGPT Retrieval Plugin enables users to connect ChatGPT to an instance of a vector database, allowing any information stored in the connected database to be used to answer questions and provide responses based on the details stored in the database. Additionally, the vector database can be utilized as a long-term storage solution for ChatGPT, allowing it to persist and store portions of user conversations beyond the short-lived memory of a browser tab.
The main functions of the ChatGPT Retrieval Plugin include:
Connecting a vector database with proprietary data to ChatGPT, allowing it to answer specific questions based on that data
Persisting personal documents and details to provide a personalized touch to ChatGPT's responses
Storing conversations with ChatGPT in the attached vector database, enabling continued conversations across multiple sessions
This functionality allows for regular updates to content stored in connected vector databases, giving the model awareness of new information without the need for costly and time-consuming retraining of the large language model (LLM).
This article presents an overview of various vector database providers supported by the plugin, highlighting their unique features, performance, and pricing. The choice of a vector database provider depends on specific use cases and requirements, and each provider necessitates the use of distinct Dockerfiles and environment variables. Detailed instructions for setting up and using each provider can be found in their respective documentation at /docs/providers/<datastore_name>/setup.md.
Pinecone is a managed vector database engineered for rapid deployment, speed, and scalability. It uniquely supports hybrid search and is the sole datastore that natively accommodates SPLADE sparse vectors. For comprehensive setup guidance, refer to /docs/providers/pinecone/setup.md.
Weaviate is an open-source vector search engine designed to scale effortlessly to billions of data objects. Its out-of-the-box support for hybrid search makes it ideal for users who need efficient keyword searches. Weaviate can be self-hosted or managed, offering flexible deployment options. For extensive setup guidance, refer to /docs/providers/weaviate/setup.md.
Zilliz is a managed, cloud-native vector database tailored for billion-scale data. It boasts a plethora of features, including numerous indexing algorithms, distance metrics, scalar filtering, time-travel searches, rollback with snapshots, full RBAC, 99.9% uptime, separated storage and compute, and multi-language SDKs. For comprehensive setup guidance, refer to /docs/providers/zilliz/setup.md.
Milvus is an open-source, cloud-native vector database that scales to billions of vectors. As the open-source variant of Zilliz, Milvus shares many features with it, such as various indexing algorithms, distance metrics, scalar filtering, time-travel searches, rollback with snapshots, multi-language SDKs, storage and compute separation, and cloud scalability. For extensive setup guidance, refer to /docs/providers/milvus/setup.md.
Qdrant is a vector database that can store documents and vector embeddings. It provides self-hosted and managed Qdrant Cloud deployment options, catering to users with diverse requirements. For comprehensive setup guidance, refer to /docs/providers/qdrant/setup.md.
Redis is a real-time data platform suitable for an array of applications, including AI/ML workloads and everyday use. By creating a Redis database with the Redis Stack docker container, Redis can be employed as a low-latency vector engine. For a hosted or managed solution, Redis Cloud is available. For extensive setup guidance, refer to /docs/providers/redis/setup.md.
LlamaIndex serves as a central interface to connect your LLMs with external data. It offers a collection of in-memory indices over structured and unstructured data for use with ChatGPT. Unlike conventional vector databases, LlamaIndex supports a wide array of indexing strategies (for example tree, keyword table, knowledge graph) optimized for various use-cases. It is lightweight, user-friendly, and requires no additional deployment. Users need only specify a few environment variables and, optionally, point to an existing saved Index JSON file. However, metadata filters in queries are not yet supported. For comprehensive setup guidance, refer to /docs/providers/llama/setup.md.
The Weaviate Retrieval Plugin can be used in various applications, such as creating a private, customized version of ChatGPT tailored to an organization's internal documents or personalizing ChatGPT based on individual user details. By connecting the plugin to Weaviate, users can make ChatGPT more useful and relevant to their specific needs.
The Weaviate Retrieval Plugin can be used to create a customized version of ChatGPT trained on a company's internal documents, enabling it to act as a human resources chatbot. This can provide employees with easy access to information about onboarding processes, health benefits, and more.
The plugin also enables the customization of ChatGPT around personal details, such as information about friends or languages spoken by the user. By storing these details in Weaviate, ChatGPT can provide more tailored and personalized responses.
One of the most powerful applications of the Weaviate Retrieval Plugin is its ability to store and reference previous conversations with ChatGPT. By persisting these conversations in Weaviate, ChatGPT can recall past interactions and provide more contextually relevant responses.