CtrlK
Template:Infobox software
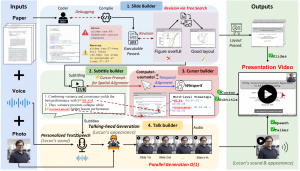
Paper2Video (Paper2Video: Automatic Video Generation from Scientific Papers) is a research project from Show Lab at the National University of Singapore that formalizes and evaluates automatic generation of academic presentation videos directly from scientific papers. It comprises (1) the Paper2Video Benchmark, a curated set of 101 paper–video pairs with slides and speaker metadata, and (2) PaperTalker, a multi‑agent framework that turns a paper (plus a reference image and short voice sample) into a narrated presentation video with slides, subtitles, cursor highlights, and an optional talking‑head presenter.[1][2] Code and data are open‑sourced under the MIT license on GitHub and the benchmark is hosted on Hugging Face.[3][4]
The name Paper2Video refers to both the benchmark and the overall project; the video‑generation agent is called PaperTalker. The work targets long‑context, multimodal inputs (text, figures, tables) and coordinated outputs across slides, subtitles, speech, cursor motion, and an optional talking head, with evaluation focused on faithfulness, audience comprehension, and author visibility rather than purely natural‑video realism.[1][2]
The benchmark pairs recent conference papers with the authors’ presentation videos, original slide decks (when available), and presenter identity metadata. Data sources include public platforms such as YouTube and SlidesLive.[1]
| Item | Value (aggregate) |
|---|---|
| Number of paper–video pairs | 101 |
| Average words per paper | ~13.3K |
| Average figures per paper | ~44.7 |
| Average pages per paper | ~28.7 |
| Average slides per presentation | ~16 |
| Average talk duration | ~6 minutes 15 seconds (range: 2–14 minutes) |
Sources: project page, dataset card, and paper.[2][4][1]
A domain breakdown reported in the paper is:
| Area | Count (papers) |
|---|---|
| Machine learning (for example NeurIPS, ICLR, ICML) | 41 |
| Computer vision (for example CVPR, ICCV, ECCV) | 40 |
| Natural language processing (for example ACL, EMNLP, NAACL) | 20 |
Each instance includes the paper’s full LaTeX project, an author‑recorded presentation video (slide and talking‑head streams), and speaker identity (portrait and short voice sample). For ~40% of entries, original slide PDFs are also collected, enabling reference‑based slide evaluation.[1]
Paper2Video proposes four tailored metrics for academic presentation videos, using vision‑language models (VLMs) and VideoLLMs as automated judges where appropriate.[1]
| Metric | What it measures | How it is operationalized |
|---|---|---|
| Meta Similarity | Alignment of generated assets with human‑authored ones (slides, subtitles; speech timbre) | A VLM compares generated slide–subtitle pairs to the human versions on a five‑point scale; speech similarity uses embedding cosine similarity on uniformly sampled 10‑second clips.[1] |
| PresentArena | Overall preference/quality in head‑to‑head comparisons | A VideoLLM performs double‑order pairwise comparisons between generated and human‑made presentation videos; winning rate is the metric (order flipping reduces bias).[1] |
| PresentQuiz | Information coverage and comprehension | Multiple‑choice questions are generated from the source paper; a VideoLLM “watches” the video and answers; overall accuracy is reported.[1] |
| IP Memory | Memorability and the audience’s ability to associate authors with their work | A recall task asks a VideoLLM to match brief video clips to a relevant question given a speaker image; accuracy reflects retention/associative memory.[1] |
PaperTalker is a multi‑agent pipeline that converts a paper into a narrated presentation video. The pipeline is designed to scale slide‑wise in parallel for efficiency.[1]
Implementation notes. The repository uses the Tectonic LaTeX engine for slide compilation and documents configuration for commercial and local VLM/LLM back‑ends. Recommended back‑ends include GPT‑4.1 or Gemini 2.5 Pro (with local Qwen variants supported); the minimum recommended GPU for the full pipeline is an NVIDIA A6000 (48 GB). A “light” mode without the talking head is provided, along with example commands for full or fast generation.[3]
On automated metrics, PaperTalker reports the strongest performance among automatic baselines on the Paper2Video Benchmark; human‑made videos remain top‑rated in user studies, with PaperTalker ranking second and ahead of other automatic methods.[1]
Ablations (cursor highlighting). A localization QA shows a large gain from explicit cursor guidance:
| Method/variant | Accuracy |
|---|---|
| PaperTalker (without cursor) | 0.084 |
| PaperTalker (with cursor) | 0.633 |
Source: paper (Table 4).[1]
Runtime snapshot (per paper, representative setting).
| Method | Time (min) | Notes |
|---|---|---|
| PaperTalker (full) | 48.1 | Includes talking head |
| PaperTalker (without talker) | 15.6 | “Fast” variant |
| PaperTalker (without parallelization) | 287.2 | For comparison |
Slide‑wise parallelization yields over 6× speed‑up versus sequential generation in the agentic pipeline.[1]
Paper2Video contrasts with adjacent efforts in document‑to‑media automation and evaluation: