CtrlK
DALL-E is an artificial intelligence (AI) system developed by OpenAI than can create images from a text description (figure 1). [1] The AI system's name derives from a combination of Spanish surrealist artist Salvador Dali and WALL-E, the character from Pixar. [2] [3]
Its deep learning image synthesis model has been trained on a set of millions of images from the internet. By utilizing latent diffusion, a technique used to learn associations between words and images, it can generate images in different artistic styles following a user's natural language prompt (figure 1). According to OpenAI, diffusion "starts with a pattern of random dots and gradually alters that pattern towards an image when it recognizes specific aspects of that image." [1] [3] [4] The system is constantly updating its datasets in order to interpret correctly the prompts given, creating a set of images that correspond closely to the users' intent. [3]
According to Singh et al. (2021), DALL-E has shown "impressive ability to systematically generalize for zero-shot image generation. Trained with a dataset of text-image pairs, it can generate plausible images even from an unfamiliar text prompt such as “avocado chair” or “lettuce hedgehog”, a form of systematic generalization in the text-to-image domain." Zero-shot imagination, composing a new scene different from the training distribution, is an ability that is at the core of human intelligence. Nevertheless, in terms of compositionality, its something that can be expected from the AI system since the text prompt already provides a composable structure. [5]
DALL-E is a competitor to Midjourney.
DALL-E has the capability to create original artworks in different styles, which includes photorealism, paintings, and emoji. [2] It can also generate anthropomorphized versions of animals and objects and combining different concepts, styles and attributes in plausible ways. Another available capability of the system is to realistically edit existing images, adding or removing elements while maintaining a correct balance of shadows, reflection, and textures without explicit instructions. [1] [2] [6] According to Huang (2022), the AI "showed the ability to 'fill in the blanks' to infer appropriate details without specific prompts such as adding Christmas imagery to prompts commonly associated with the celebration, and appropriately-placed shadows to images that did not mention them." [2] Furthermore, DALL-E can expand images beyond is original canvas and create different variation from an original image. [2]
Huang (2022) has also noted that DALL-E can produce images from a wide spectrum of arbitrary descriptions from different viewpoints with a low rate of failure and that with its visual reasoning ability it can solve Raven's Matrices--visual tests to measure intelligence. [2]
However, the program is not without its limitations. For example, it has difficulties distinguishing "A yellow book and a red vase" from "A red book and a yellow vase." Also, asking for more than 3 objects, using negation, numbers, and connected sentences in the text prompt can lead to mistakes and features attributed to the wrong objects. [2]
On July 20, 2022, OpenAI announced that the users would get full usage rights to commercialize the images created. This included the right to reprint, sell, and merchandise. However, OpenAI does not relinquish its right to commercialize images created by the users. [7]
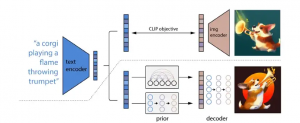
DALL-E was developed and announced at the same time with CLIP, a Contastive Language-Image Pretraining. These two models are different but correlated. CLIP, a zero-shot system, was trained with 400 million pairs of images "with text captions scraped from the internet". [2] [3]
Its relation to the image generation system is to understand and rank DALL-E's output by predicting which caption fits best for an image from a list of thousands of captions selected from a dataset. Therefore, CLIP creates text descriptions for images generated by DALL-E, which does the opposite-composing images from text, a method called unCLIP. [2] [3]
OpenAI has continually worked on the safety and security of DALL-E to prevent abuses during image creation. The company has said that they've enhanced their "safety system, improving the text filters and tuning the automated detection and response system for content policy violations.” These safety features prevent users from creating violent or harmful content by removing it from the machine learning datasets. The same applies to text prompts. It also prevents deepfakes by not allowing the creation of photorealistic images of the faces of real people, including public figures. [3]
The second version of the software, DALL-E 2, is available as an API so developers can build the system into their apps, websites, and services. Microsoft has added it to Bing and Microsoft Edge with Image Creator tool. CALA, a fashion design app, is using the DALL-E 2 API, allowing its users to improve design ideas from text prompts. Mixtiles, a photo startup, is also already using the API in its own system for an artwork-creation flow to help users. [8]
There are several applications of AI-generated images for content creation. For example, to use DALL-E to generate images of products not yet in existence or images that are too costly or difficult to photograph. [3]
In the future, users could use multiple AI tools, combining them to create fully animated art. Gil Perry, CEO of D-ID has said that "we’re seeing that people are layering different AI tools to produce even more creative content. An image of a person created on DALL-E can be animated and given voice using D-ID (AI-generated text-to-video). A landscape created in Dreamstudio can turn into an opening shot of a movie, accompanied by music composed on Jukebox." [3]
There are four key concepts that are at the base of how the current version of DALL-E works:
OpenAI started working on a text generator before DALL-E. In 2019, GPT-2 was created; with 1.5 billion parameters and trained on 8 million web pages, the model had the goal to predict the next word within a text. Its next version, GPT-3, would become the the preliminary model for DALL-E, changed to generate images instead of text. [2] [3]
On January 2021, DALL-E was introduced. A year later, on April 2022, OpenAI introduced DALL-E 2, an improved version of the AI software. [1] [2] [4] This new version entered public beta in July of the same year. [10] At the same time, a pricing model was instituted. [4]
In September 2022, OpenAI announced that the waitlist for DALL-E was removed. This way anyone could now sign up to the service and use it. [4]
Finally, in November 2022, the image-generating AI system was made available as an API. At that time, more than 3 million users were using the DALL-E, creating more than 4 million images per day. [8]
According to OpenAI, DALL-E 2 started as a research project and ended up as the new version of the system to generate original synthetic images from an input text. [1] [11] This new version has several improvements (figure 3) including higher resolution, greater comprehension and new capabilities like inPainting and Outpainting. [1] [3] The company also continues to invest in safety by improving the prevention of harmful generation and curbing misuse. [1]
DALL-E 2 uses 3.5 billion parameters, with an added 1.5 billion parameters to enhance resolution, while the first version used 12 billion. It generates images with four times better resolution and, overall, its creations are more realistic and accurate. [3] [9]


The second version of DALL-E has new functionalities like Inpainting and Outpainting. In the first one, generated or uploaded images can be edited by the program, adapting the new objects to the style present in that part of the image (figure 4); textures and reflections are updated according to the edits on the original image. [10] [9] Also, it can edit images of human faces. [12] The second feature, outpainting, allows users to expand the original image beyond its borders. It also takes into account existing shadows, reflections and textures while extending the borders of the original image with new content. The AI software can also create larger images in different aspect ratios. [3] [4] [10]


Marcus et al. (2022) listed several observations about DALL-E 2 resulting from test done on the program.
DALL-E offers to new users 50 credits. These can be bought in froups of 115 for $15. [4] For the DALL-E 2 API the pricing varies by resolution: 1024x1024 images cost $0.02 per image; 512×512 images are $0.018; and 256×256 images cost $0.016. [8]
The main concerns regarding the use of AI image generating software can be grouped into three main groups: artistic integrity, copyright issues, and violent images / deepfakes.
With new AI sytems capable of generating artwork form text prompts, some have suggested issues about artistic integrity; if anyone can type a text and generate a beautiful artwork or expand existing works with outpainting, there's implications for the future of art. However, the same technology allows for a new generation of artists that were held back by lack of time, no proper art education or physical disabilities. [10] [13]
OpenAI gave users commercial rights over their images, avoidign some tricky questions regarding intellectual property issues. Since the users only contribute with the text prompts and the images are machine-made, results are not likely to be copyrightable. [13] In August 2022, Getty images banned the upload and sale of images generated by DALL-E 2. Other sites like Newgrounds, PurplePort and FurAffinity did the same with the main issue being "unaddressed right issues" according to Getty Images CEO Craig Peters since the training datasets contain copyrighted images. Contrarily to this decision, Shuttertock announced that it would begin using DALL-E 2 for content. [8]
Regarding deepfakes, other image generating systems like Stable Diffusion are already being used to generate deepfakes of celebrities. [2] [12] OpenAI has a security system in place to block that type of content. It also bans "'political' content, along with content that is 'shocking,' 'sexual,' or 'hateful,' to name just a few of the company’s capacious categories of forbidden images." [13]