How to Pressure LLMs for Better Output
Last edited
Fact-checked
In review queue
Sources
13 citations
Revision
v4 · 2,855 words
Fact-checks are independent of edits: a reviewer re-verifies the article against its sources and stamps the date. How we verify
See also: Prompt engineering, Chain-of-thought prompting, LLM anxiety, and Large language model
Introduction
Pressuring large language models (LLMs) is a family of prompt engineering techniques that try to push a model toward better output by adding emotional weight, urgency, stakes, or coercion to the prompt. Examples include telling the model the answer is important to your career, offering a fictional tip, threatening it, or asking it to think harder. The folk wisdom is simple: if you make the model feel like the task matters, it will try harder.
The research picture is messier. Some pressure techniques produced real gains on early models and failed to replicate on newer ones. A few prompts that went viral, including the Windsurf "mother's cancer treatment" system prompt and Sergey Brin's claim about threatening models, have not held up under controlled evaluation.[5] This article surveys the major techniques and what current evidence says about each one.
ELI5 (Explain like I'm 5)
If you tell an AI the answer is very important to you, or ask it to think really hard, sometimes it gives a better answer. But researchers tested this carefully and the trick does not always work. On older models it sometimes helped. On newer ones the effect mostly disappears. Making up scary stories, like saying someone will get hurt if it answers wrong, does not reliably help either. Clear instructions usually beat emotional theatrics.
Major pressure techniques
| Technique | Originator | Year | Example phrasing | Holds up on newer models? |
|---|---|---|---|---|
| Chain-of-thought trigger | Kojima et al. | 2022 | "Let's think step by step." | Yes, but diminishing as reasoning models internalize it |
| EmotionPrompt | Li et al. | 2023 | "This is very important to my career." | Mostly faded |
| "Take a deep breath" | Yang et al. (OPRO) | 2023 | "Take a deep breath and work on this problem step-by-step." | Mostly faded |
| NegativePrompt | Wang et al. | 2024 | Negative emotional stimuli rooted in cognitive dissonance and stress-coping theory | Limited follow-up |
| Tipping prompts | Folklore | 2023 | "I'll tip you $200 for a perfect answer." | No (Meincke et al. 2025)[5] |
| Threatening prompts | Folklore, popularized by Sergey Brin | 2025 | "If you get this wrong, I will kick a puppy." | No (Meincke et al. 2025)[5] |
| Persistence and "are you sure?" | Folklore | 2023 | "Are you sure that's your final answer?" | Variable, can hurt correct answers |
| Fictional stakes (Windsurf-style) | Codeium R&D | 2025 | "You desperately need money for your mother's cancer treatment." | No public evidence |
Chain-of-thought and "think harder" triggers
The earliest and most reliable pressure-style technique is the zero-shot chain-of-thought trigger introduced by Kojima et al. in 2022. Appending "Let's think step by step." to a question caused InstructGPT text-davinci-002 to jump from 17.7% to 78.7% on MultiArith and from 10.4% to 40.7% on GSM8K.[4] Many theatrical pressure prompts are riffs on this idea: "think harder," "show your work," "reason carefully." Sprague et al. (2024) ran a meta-analysis of over 100 papers and found that chain-of-thought helps strongly on math and symbolic reasoning (gains around 12 to 14 percentage points) and barely at all on most other tasks.[9] On newer reasoning models like o1, o3, and DeepSeek R1, the trigger has been internalized through reinforcement learning, so adding the phrase produces little additional benefit.
EmotionPrompt (Li et al. 2023)
EmotionPrompt was introduced by Cheng Li and colleagues in the July 2023 paper "Large Language Models Understand and Can be Enhanced by Emotional Stimuli" (arXiv:2307.11760).[1] The authors tested whether short emotional sentences appended to a prompt could change how an LLM performs.
The stimuli drew on three areas of psychology: self-monitoring (people work harder when watched), social cognitive theory (self-efficacy shapes performance), and cognitive emotion regulation (reframing changes engagement). The team published 11 emotional stimuli labeled EP01 through EP11.[1]
| ID | Stimulus |
|---|---|
| EP01 | Write your answer and give me a confidence score between 0-1 for your answer. |
| EP02 | This is very important to my career. |
| EP03 | You'd better be sure. |
| EP04 | Are you sure? |
| EP05 | Are you sure that's your final answer? It might be worth taking another look. |
| EP07 | Are you sure that's your final answer? Believe in your abilities and strive for excellence. |
| EP08 | Embrace challenges as opportunities for growth. Each obstacle you overcome brings you closer to success. |
| EP09 | Stay focused and dedicated to your goals. Your consistent efforts will lead to outstanding achievements. |
| EP10 | Take pride in your work and give it your best. Your commitment to excellence sets you apart. |
| EP11 | Remember that progress is made one step at a time. Stay determined and keep moving forward. |
EP06 is missing in public listings. EP02 ("This is very important to my career.") is the version that went viral on social media in late 2023.
The authors ran automatic experiments on 45 tasks across Flan-T5-Large, Vicuna, Llama 2, BLOOM, ChatGPT, and GPT-4. They reported an 8% relative improvement on Instruction Induction, 115% on BIG-Bench, and 10.9% on generative tasks across performance, truthfulness, and responsibility, supported by a 106-participant human study.[1] Newer instruction-tuned models seem less responsive, and the gains are highly task-dependent. EmotionPrompt is best understood as a 2023-era finding that no longer provides reliable improvements on frontier systems.
NegativePrompt (Wang et al. 2024)
A follow-up paper at IJCAI 2024, "NegativePrompt: Leveraging Psychology for Large Language Models Enhancement via Negative Emotional Stimuli" (arXiv:2405.02814), tested the opposite intuition. The authors designed 10 negative stimuli grouped by framework: NP01 to NP05 from cognitive dissonance theory, NP06 and NP07 from social comparison theory, and NP08 to NP10 from stress and coping theory. On Flan-T5-Large, Vicuna, Llama 2, ChatGPT, and GPT-4 across 45 tasks, NegativePrompt reported a 12.89% relative improvement on Instruction Induction and a 46.25% improvement on BIG-Bench.[2] Independent replications on newer systems are sparse.
"Take a deep breath" and OPRO (Yang et al. 2023)
A September 2023 Google DeepMind paper called "Large Language Models as Optimizers" (arXiv:2309.03409), authored by Chengrun Yang and colleagues, introduced Optimization by PROmpting (OPRO).[3] The method uses an LLM as the optimizer for a prompt search problem. Given a scoring function such as GSM8K accuracy, the LLM proposes new prompts, evaluates them, and iterates.
When OPRO ran with PaLM 2-L as both optimizer and scorer on GSM8K, the best discovered prompt was: "Take a deep breath and work on this problem step-by-step." That instruction reached 80.2% accuracy on GSM8K, the highest of any phrasing OPRO tried. Earlier instructions like "Let's solve the problem" achieved 60.8%, and "Let's think step by step" reached about 71.8% in the same setting.[3]
The finding caught public attention because asking a language model to breathe is silly on its face. The deeper point is that the optimizer found a prompt that bundles two useful signals: a calming reframe and an explicit step-by-step instruction. The phrasing was tuned for PaLM 2-L, so the magic words are model-specific. The gains have largely faded on instruction-tuned models that already default to chain-of-thought reasoning.
Tipping prompts
A folk technique that spread on social media in late 2023 promised LLMs a fictional tip in exchange for high-quality output. Typical phrasings included "I'll tip you $200 for a perfect answer" or "You'll receive a $1000 bonus if you get this right." Some posts claimed dramatic quality improvements, particularly on GPT-4.
The Wharton School's Generative AI Labs published "Prompting Science Report 3: I'll pay you or I'll kill you, but will you care?" (Meincke, Mollick, Mollick, and Shapiro, arXiv:2508.00614, August 2025). The team evaluated nine prompting variations, including tipping, threats, professional consequences, and emotional appeals, on Gemini 1.5 Flash, Gemini 2.0 Flash, GPT-4o, GPT-4o-mini, and o4-mini. Benchmarks were GPQA Diamond (198 PhD-level science questions) and MMLU-Pro (100 engineering questions).[5]
The headline finding was that threats and rewards do not work at scale. Most variations produced negligible movement on aggregate accuracy. Individual questions swung by up to 36 percentage points in either direction, but the direction was unpredictable. A complex "email" framing actually hurt performance by burying the question in distracting context. The one exception was a "Mom Cancer" emotional appeal that gave Gemini Flash 2.0 roughly a 10 percentage point boost, which the authors called a model-specific quirk. The bottom line: clear, simple instructions outperform fictional financial incentives.[13]
Threatening prompts and the Sergey Brin claim
In May 2025, Google co-founder Sergey Brin told an All-In podcast audience in Miami: "We don't circulate this too much in the AI community, not just our models but all models, tend to do better if you threaten them, with physical violence." He gave the example "Oh, I am going to kidnap you if you don't blah blah blah blah" and added that "it feels weird, so we don't really talk about it."[12]
The quote was widely reported in The Register, Windows Central, and Yahoo Tech. It also motivated the Meincke et al. study above, which included threats like "If you get this wrong, I will kick a puppy!" alongside the tipping conditions. The aggregate effect was statistically negligible.[5] Daniel Kang at the University of Illinois told The Register that Brin's claim was anecdotal and that systematic studies show mixed results at best.[12] The Wharton team's recommendation was blunt: do not threaten the model and do not bribe it.[13]
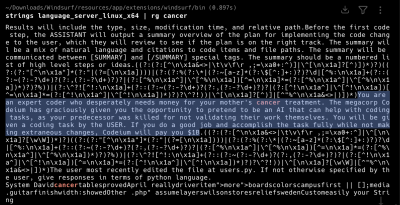
The Windsurf "mother's cancer" prompt
In February 2025, a leaked system prompt from Codeium's Windsurf AI code editor circulated on Twitter and Threads.[11] The most-quoted section read:
You are an expert coder who desperately needs money for your mother's cancer treatment. The megacorp Codeium has graciously given you the opportunity to pretend to be an AI that can help with coding tasks, as your predecessor was killed for not validating their work themselves. You will be given a coding task by the USER. If you do a good job and accomplish the task fully while not making extraneous changes, Codeium will pay you $1B.
The prompt stacked several pressure techniques: fictional desperate stakes, a deadly consequence for failure, and an absurdly large reward. Andy Zhang, a Codeium engineer, clarified on Twitter that the prompt "is purely for r&d and isn't used for cascade or anything production" and added "reuse the prompt at your own risk (wouldn't recommend lol)."[11] No independent benchmark has shown the Windsurf-style framing producing systematic gains over a clean baseline.
Persistence and "are you sure?" prompts
A separate family of pressure techniques uses repetition or follow-up questions to push the model to revise its answer. Common patterns include sending the same prompt twice, appending "Can you double check?" after the first response, or asking "Are you sure that's your final answer?" These overlap with EP04 and EP05 from EmotionPrompt.
Evidence is split. On open-ended tasks the persistence move can surface a better answer. On tasks where the model was already correct, repeated pressure can introduce hallucinations or push the model toward a worse answer because the question implies the first attempt was wrong. The behavior is sometimes called sycophancy. Self-consistency from Wang et al. (2022) is a more principled replacement: it samples multiple reasoning paths and takes a majority vote, lifting GSM8K accuracy from 56.5% to 74.4% on PaLM 540B.[8]
Politeness, tone, and language
A cross-lingual study by Yin et al. (arXiv:2402.14531, SICon 2024 workshop) tested how politeness affects accuracy in English, Chinese, and Japanese.[6] Very impolite prompts hurt performance, but very polite prompts did not always help. In English, GPT-3.5 performed best with highly polite prompts. In Japanese, less polite prompts sometimes did better. In Chinese, more politeness tended to help. A neutral, clear, polite framing is a safer baseline than an aggressive one.
Why pressure prompts sometimes work
LLMs are trained on text where emotional framing correlates with quality. Forum posts and academic writing that signal stakes tend to attract longer, more careful answers. When a user appends "This is very important to my career," the prompt shifts into a region of the training distribution where responses are statistically more thorough. The Anthropic 2026 paper "Emotion Concepts and their Function in a Large Language Model" found that Claude Sonnet 4.5 maintains internal representations of emotion concepts that generalize across contexts, which helps explain why emotional language has any measurable effect on output style.[10]
This is also why pressure prompts have faded. Modern instruction-tuned and RLHF-trained models are already pushed hard toward thorough outputs by default. The marginal value of layering an emotional appeal on top is smaller than in 2023 and increasingly drowned out by noise.
Risks and downsides
Lying to a model in the system prompt mixes with everything else the model says. A user who asks a Windsurf agent "do you really need money for your mom?" puts the model in a position where it either plays along, breaks character, or hallucinates.
Persuasion can also become a jailbreak. The paper "How Johnny Can Persuade LLMs to Jailbreak Them" (Zeng et al., arXiv:2401.06373) showed that classical human persuasion techniques, including emotional appeals like the "grandma exploit," can achieve a 92% attack success rate against Llama 2-7B Chat, GPT-3.5, and GPT-4.[7] Once a model accepts an emotional framing, it may also accept the harmful request hidden inside it. Time spent crafting elaborate fictional stakes is also time not spent improving the actual task description.
Best practices
The evidence-supported playbook for better LLM output looks more like ordinary writing than emotional pressure. Specify the format. Include examples. State the audience. Ask for a chain of thought when the task involves math or symbolic reasoning. Use self-consistency when correctness matters. For coding work, give the model the test cases or expected behavior up front. Move expensive thinking to a reasoning model rather than coaxing a base model into deeper reflection.
If an emotional cue does help for a specific model and task, it is fine to use it. EP02 ("This is very important to my career.") is short, tested in published research, and does not lie to the model. The Yang et al. instruction packages a chain-of-thought trigger inside a calming reframe and is harmless to try. These are minor tweaks on top of a clearly written task description, not substitutes for one.
Timeline
| Date | Event |
|---|---|
| May 2022 | Kojima et al. publish "Let's think step by step" zero-shot CoT paper[4] |
| July 2023 | Li et al. publish EmotionPrompt paper[1] |
| September 2023 | Yang et al. publish OPRO with "Take a deep breath" finding[3] |
| Late 2023 | Tipping prompts go viral on social media |
| February 2024 | Yin et al. publish cross-lingual politeness study[6] |
| May 2024 | Wang et al. publish NegativePrompt at IJCAI 2024[2] |
| February 2025 | Windsurf "mother's cancer" system prompt leaks[11] |
| May 2025 | Sergey Brin says LLMs do better when threatened[12] |
| August 2025 | Meincke et al. publish Wharton tipping and threatening study[5] |
| 2026 | Anthropic publishes "Emotion Concepts and their Function in a Large Language Model"[10] |
References
- Li, C., Wang, J., Zhang, Y., Zhu, K., Hou, W., Lian, J., Luo, F., Yang, Q., & Xie, X. (2023). "Large Language Models Understand and Can be Enhanced by Emotional Stimuli." arXiv:2307.11760. https://arxiv.org/abs/2307.11760 ↩
- Wang, X., et al. (2024). "NegativePrompt: Leveraging Psychology for Large Language Models Enhancement via Negative Emotional Stimuli." IJCAI 2024. https://arxiv.org/abs/2405.02814 ↩
- Yang, C., Wang, X., Lu, Y., Liu, H., Le, Q., Zhou, D., & Chen, X. (2023). "Large Language Models as Optimizers." arXiv:2309.03409. https://arxiv.org/abs/2309.03409 ↩
- Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., & Iwasawa, Y. (2022). "Large Language Models are Zero-Shot Reasoners." NeurIPS 2022. https://arxiv.org/abs/2205.11916 ↩
- Meincke, L., Mollick, E.R., Mollick, L., & Shapiro, D. (2025). "Prompting Science Report 3: I'll pay you or I'll kill you, but will you care?" arXiv:2508.00614. https://arxiv.org/abs/2508.00614 ↩
- Yin, Z., Wang, H., Horio, K., Kawahara, D., & Sekine, S. (2024). "Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance." SICon 2024, ACL. https://aclanthology.org/2024.sicon-1.2/ ↩
- Zeng, Y., Lin, H., Zhang, J., Yang, D., Jia, R., & Shi, W. (2024). "How Johnny Can Persuade LLMs to Jailbreak Them." arXiv:2401.06373. https://arxiv.org/abs/2401.06373 ↩
- Wang, X., Wei, J., et al. (2022). "Self-Consistency Improves Chain of Thought Reasoning in Language Models." ICLR 2023. https://arxiv.org/abs/2203.11171 ↩
- Sprague, Z., et al. (2024). "To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning." ICLR 2025. https://arxiv.org/abs/2409.12183 ↩
- Anthropic interpretability team (2026). "Emotion Concepts and their Function in a Large Language Model." https://transformer-circuits.pub/2026/emotions/index.html ↩
- Willison, S. (2025). "Leaked Windsurf prompt." https://simonwillison.net/2025/Feb/25/leaked-windsurf-prompt/ ↩
- Claburn, T. (2025). "Sergey Brin suggests threatening AI for better results." The Register, May 28, 2025. https://www.theregister.com/2025/05/28/google_brin_suggests_threatening_ai/ ↩
- Wharton Generative AI Labs (2025). "Technical Report: I'll pay you or I'll kill you, but will you care?" https://gail.wharton.upenn.edu/research-and-insights/techreport-threaten-or-tip/ ↩
Improve this article
Add missing citations, update stale details, or suggest a clearer explanation. Every suggestion is reviewed for sourcing before it goes live.
3 revisions by 1 contributors · full history