Segment Anything Model and Dataset (SAM and SA-1B)
Last edited
Fact-checked
In review queue
Sources
28 citations
Revision
v7 · 8,678 words
Fact-checks are independent of edits: a reviewer re-verifies the article against its sources and stamps the date. How we verify
See also: Papers, Models and Datasets See also: Computer Vision Papers, Computer Vision Models and Computer Vision Datasets
Segment Anything Model (SAM) is a promptable image segmentation foundation model released by Meta AI on April 5, 2023 that lets users "cut out" any object in an image with a single click, box, or mask prompt, and generalizes zero-shot to unfamiliar objects and images without additional training [1] [2]. SAM was trained on SA-1B, the largest segmentation dataset published at the time, with over 1.1 billion masks across about 11 million licensed, privacy-preserving images [1] [3]. The original paper opens by stating: "We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation," and reports zero-shot results that are "often competitive with or even superior to prior fully supervised results" [1]. The model weights are released under the permissive Apache 2.0 license, while the SA-1B dataset is released under a custom research-only license [1] [3].
Introduction
Model introduction
Segment Anything Model (SAM) is an artificial intelligence model developed by Meta AI. The model lets users "cut out" any object within an image using a single click. It is a promptable segmentation system that can generalize to unfamiliar objects and images without additional training [1] [2].
The original SAM was introduced on April 5, 2023, in a research paper titled "Segment Anything" by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick at Meta AI Research (FAIR) [1]. The paper was published as arXiv:2304.02643 and later appeared at ICCV 2023, where it won a Best Paper Honorable Mention. The model and the accompanying SA-1B dataset were released the same day on segment-anything.com.
Project introduction
Segment Anything is a project aimed at democratizing image segmentation by providing a foundation model and dataset for the task. Image segmentation involves identifying which pixels in an image belong to a specific object, and it is a core component of computer vision. Building accurate segmentation models for specific tasks usually requires specialized work by technical experts, access to AI training infrastructure, and large amounts of carefully annotated data [2].
Before SAM, segmentation research was fragmented across narrow benchmarks. COCO, Cityscapes, ADE20K, LVIS, and Pascal VOC each defined their own label vocabularies, and a model trained on one would usually fail on another. SAM proposed a different way of framing the task: instead of asking the model to classify pixels into a closed set of categories, ask it to predict the mask of whatever the user points to. The category labels are no longer the model's problem; segmentation becomes a general-purpose pixel-grouping primitive. This reframing is the reason SAM is treated as a foundation model for vision rather than as just another segmentation network.
Segment Anything Model (SAM) and SA-1B Dataset
On April 5, 2023, the Segment Anything project introduced the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), as detailed in a research paper. The SA-1B dataset was, at the time of release, the largest segmentation dataset ever published. The SA-1B dataset is available for research purposes under a custom research license, while the Segment Anything Model is released under the Apache 2.0 license [1] [3].
SAM is designed to reduce the need for task-specific modeling expertise, training compute, and custom data annotation. Its goal is to create a foundation model for image segmentation that can be trained on diverse data and adapt to specific tasks, similar to the prompting used in natural language processing models. Segmentation data of the kind required for training such a model is not readily available, unlike images, videos, and text. To solve that gap, the project set out to develop a general, promptable segmentation model and to simultaneously create a segmentation dataset on an unprecedented scale [1].
What is the promptable segmentation task?
SAM is built around a single idea that the paper calls the promptable segmentation task. Given any prompt that specifies what to segment, the model must return a valid mask. "Valid" means that for ambiguous prompts (such as a single point on a person's shirt, which could refer to the shirt, the person, or the small pocket on the shirt), at least one of the returned masks should be a reasonable segmentation. This is similar in spirit to how language models are trained on next-token prediction: a deceptively simple objective that turns out to be a strong general capability when scaled with enough data [1].
From that task definition, three properties follow:
- Composable prompts. Points, boxes, masks, and (in research code) text embeddings can all be fed to the same prompt encoder. A practitioner can mix prompt types in a single call, or feed prompts produced by another system (an object detector, an eye tracker, a text encoder).
- Ambiguity-aware outputs. SAM produces three candidate masks per prompt by default, intended to correspond loosely to the whole object, a part, and a subpart. A separate Intersection over Union (IoU) prediction head ranks them.
- Zero-shot transfer. Because the model never relied on a closed label set, it can be pointed at imagery from medical scans, satellite tiles, microscopy, sketches, or video frames at inference time. The training distribution biases what it does well, but the prompt interface keeps working on any pixels.
Meta deliberately separated the heavy backbone work (the image encoder) from the cheap user-interactive work (the prompt encoder and mask decoder). In practice this means the image only needs to be processed once. Subsequent clicks, boxes, or refinements run in milliseconds. The interactive demo at segment-anything.com showed this clearly: a user could click around an image at near-instant latency in a browser tab while the heavy ViT-H ran once on a server.
How is the Segment Anything Model structured?
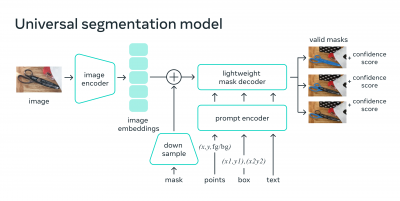
SAM's structure consists of three components:
- A Vision Transformer (ViT-H) image encoder that runs once per image and outputs an image embedding.
- A prompt encoder that embeds input prompts such as clicks, boxes, masks, or text.
- A lightweight transformer-based mask decoder that predicts object masks from the image embedding and prompt embeddings [1].
The image encoder is implemented in PyTorch and requires a GPU for efficient inference. The prompt encoder and mask decoder can either run directly with PyTorch or be converted to ONNX and run efficiently on CPU or GPU across various platforms that support the ONNX runtime.
Image encoder in detail
The image encoder is a Vision Transformer (ViT) pretrained with the Masked Autoencoder (MAE) self-supervised objective from He et al. (2022), and then fine-tuned during SAM training. It accepts images at 1024 by 1024 resolution, splits them into 16 by 16 patches, and produces a 64 by 64 grid of 256-dimensional embeddings, plus a global image embedding. The output is a dense feature map that the mask decoder can attend to. Because this is by far the most expensive part of the pipeline, it is structured to run only once per image, and the result is cached for interactive use [1].
The ViT backbone uses standard transformer blocks with multi-head self-attention and MLP layers. ViT-Huge has 32 transformer blocks, a hidden dimension of 1280, and 16 attention heads per block. SAM uses windowed attention for most blocks (with 14 by 14 windows) to keep memory feasible at high resolution, and inserts a small number of global attention blocks at fixed positions to allow long-range information flow [1].
Prompt encoder in detail
The prompt encoder distinguishes between two types of input. Sparse prompts (points and boxes) are mapped to a sum of a positional encoding and a learned type embedding. A foreground click and a background click share the same positional embedding but use different type embeddings, so a single click on a horse is interpreted differently from a click meant to exclude the rider behind it. A bounding box is represented as two corner tokens (top-left and bottom-right) with their own type embeddings [1].
Dense prompts (masks) are embedded with a small convolutional network and then added element-wise to the image embedding before the mask decoder sees it. This is how a user can refine a previous prediction: feed the prior mask back in, then add a point or two, and the decoder produces a corrected output.
The paper also describes a text-prompt path that runs CLIP's text encoder on a noun phrase, then feeds the resulting embedding into the same prompt encoder slot used for sparse prompts. This text path was reported as a research preview only and was not released in the public checkpoint. Text-prompted segmentation in practice usually relied on follow-up projects such as Grounded SAM (described below).
Mask decoder in detail
The mask decoder is a small two-way transformer with two cross-attention layers. It is the part of the system that actually reads the image features and decides which pixels to assign to the prompted object. Each decoder block does the following [1]:
- Self-attention is run over the prompt tokens.
- Prompt tokens cross-attend to image tokens, so the model can pull relevant features out of the dense map.
- An MLP updates the prompt tokens.
- Image tokens then cross-attend back to the prompt tokens, so the image features themselves are updated based on what the prompt is asking for. This two-way step is what gives the decoder its name.
After two such blocks, the model upsamples the image embedding from 64 by 64 to 256 by 256, and a small MLP applied to special output tokens produces dynamic mask filters. These filters are convolved with the upsampled feature map to yield three mask logits at 256 by 256 resolution, which are then upsampled to the original image size. A separate IoU prediction head, also driven by an output token, scores each candidate mask.
The mask decoder is intentionally tiny. The image encoder dominates parameter count and compute; the decoder has roughly 4 million parameters. This is what makes browser-side interactivity possible.
Model variants and sizes
Meta released three SAM checkpoints with different ViT backbones, all trained on SA-1B [3]:
| Variant | Backbone | Image encoder parameters | Checkpoint name |
|---|---|---|---|
| SAM ViT-B | ViT-Base/16 | ~91 million | sam_vit_b_01ec64.pth |
| SAM ViT-L | ViT-Large/16 | ~308 million | sam_vit_l_0b3195.pth |
| SAM ViT-H | ViT-Huge/16 (default) | ~636 million | sam_vit_h_4b8939.pth |
The ViT-H image encoder, the default in the original release, has 632 to 636 million parameters depending on counting conventions, while the prompt encoder and mask decoder together have roughly 4 million parameters. The ViT backbone is pretrained with a Masked Autoencoder (MAE) objective before segmentation fine-tuning [1].
Training procedure
SAM is trained with a combination of focal loss and dice loss on the mask logits, plus mean squared error on the IoU prediction head. Because the data engine often produces multiple valid masks for ambiguous prompts, the training procedure uses a minimum-over-outputs loss: of the three predicted masks, only the one with the lowest loss against the ground truth contributes to the gradient. This is the mechanism that lets the same model learn to predict three semantically distinct masks for the same input prompt without being told which mask is "correct" [1].
During training, prompts are sampled by simulating interactive segmentation. Random points are picked from the ground-truth mask. The model predicts a mask, the wrong region is identified, and additional click prompts are sampled from those error regions. This loop is iterated up to 11 times per training sample, which teaches the model to handle multi-click corrections cleanly.
Meta reported that SAM was trained for 3 to 5 days on 256 NVIDIA A100 GPUs, with a global batch size of 256 images. The training set was the SA-1B dataset described below [1].
Inference performance
The image encoder takes approximately 0.15 seconds on an NVIDIA A100 GPU. The prompt encoder and mask decoder take about 50 milliseconds on a CPU in a browser using multithreaded SIMD execution. That asymmetry is deliberate: encoding the image once is the expensive step, after which a user can produce masks interactively by sending only new prompts through the lightweight decoder [1]. SAM was trained for 3 to 5 days on 256 NVIDIA A100 GPUs.
Segment Anything Model (SAM) overview

Input prompts
SAM uses a variety of input prompts to determine which object to segment. These prompts let the model carry out many segmentation tasks without further training. SAM can be prompted with interactive points and boxes, automatically segment all objects within an image, or generate multiple valid masks when given ambiguous prompts. The model produces three candidate masks per prompt by default to handle that ambiguity, along with an Intersection over Union (IoU) confidence score for each [1].
Integration with other systems
The promptable design of SAM allows for integration with other systems. SAM can take input prompts from AR/VR headsets to select objects based on a user's gaze, and bounding box prompts from object detectors can enable text-to-object segmentation pipelines.
Extensible outputs
Output masks generated by SAM can be used as inputs to other AI systems for tracking objects in videos, image editing, lifting objects to 3D, or creative tasks like collaging.
What is zero-shot generalization in SAM?
SAM has a general understanding of what objects are, which lets it achieve zero-shot generalization to unfamiliar objects and images. In the paper, the team evaluated SAM on a suite of 23 segmentation datasets covering domains it had never seen during training (medical imagery, satellite photos, microscopy, paintings, ego-centric video frames, and more), and reported that zero-shot performance often matched or exceeded fully supervised baselines on those benchmarks [1].
Background information
Historically, segmentation has split into two main approaches: interactive segmentation and automatic segmentation. Interactive segmentation can target any object class but requires human guidance for each instance. Automatic segmentation is specific to predetermined object categories and requires substantial amounts of manually annotated data, compute, and technical expertise. SAM is a generalization of these two approaches, capable of performing both interactive and automatic segmentation [1].
Promptable segmentation
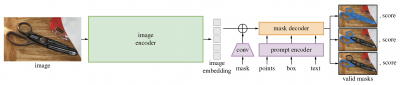
SAM is designed to return a valid segmentation mask for any prompt, whether it is foreground or background points, a rough box or mask, freeform text, or any other information indicating what to segment in an image. Trained on the SA-1B dataset of over 1 billion masks, the model generalizes to new objects and images beyond its training data, which means practitioners no longer need to collect their own segmentation data and fine-tune a model for many use cases [1].
How was the SA-1B dataset of 1 billion masks built?

To train SAM, a massive and diverse dataset was needed. The SA-1B dataset was collected using the model itself: annotators used SAM to annotate images interactively, and the newly annotated data was then used to update SAM. This process was repeated multiple times to iteratively improve both the model and the dataset [1] [2]. As the paper puts it, the team built "the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images" using "our efficient model in a data collection loop" [1].
The data engine
A data engine was built for creating SA-1B, with three stages:
- Assisted manual stage. Professional annotators used a browser-based SAM tool to label objects with point prompts; SAM was retrained periodically on the growing pool of masks. Annotators were asked to label things in order of prominence, were free to move on if a mask took longer than 30 seconds, and could label objects without naming them. In this stage SAM was retrained six times.
- Semi-automatic stage. SAM auto-generated masks for objects it was confident about, and annotators added masks for everything else, increasing mask diversity per image. The model was retrained five more times during this stage.
- Fully automatic stage. A final model annotated all images automatically using a 32 by 32 grid of foreground points, filtered with confidence and stability checks. NMS-style deduplication removed overlapping low-quality predictions. This stage produced the bulk of the 1.1 billion masks in SA-1B [1].
The entire engine ran for roughly three months at Meta. The bootstrapped design (model trains, helps annotate, gets retrained, helps annotate better) is one of the most studied parts of the project, and similar engines are now common in vision and robotics data collection [1] [2].
Dataset statistics
The final dataset includes more than 1.1 billion segmentation masks across about 11 million licensed and privacy-preserving images. The images come from a third-party photo company, are high resolution (average 1500 by 2250 pixels), and have faces and license plates blurred. SA-1B is roughly 400 times larger than any prior public segmentation dataset [1] [3].
An average SA-1B image contains roughly 100 masks, with a long tail running into the thousands. About 99 percent of those masks were generated by the fully automatic stage. The dataset has broad geographic coverage and is more representative of low- and middle-income countries than most prior vision datasets, where North American and European imagery tends to dominate [1].
| Dataset | Year | Images | Masks | Source |
|---|---|---|---|---|
| COCO | 2014 | ~328k | ~2.5M instance masks | Microsoft |
| ADE20K | 2017 | ~25k | ~707k | MIT |
| LVIS | 2019 | ~164k | ~2M | Facebook AI Research |
| Open Images V7 | 2022 | ~9M | ~2.8M masks | |
| SA-1B | 2023 | ~11M | ~1.1B | Meta AI |
Is SA-1B free to use? License terms
SA-1B is released under a custom research license that restricts its use to non-commercial research. Users must agree to terms of use that prohibit redistribution of the images, prohibit re-identification of any persons in the dataset, and require that derived models trained solely on SA-1B inherit the same usage constraints. The license is more restrictive than CC BY 4.0; this is one reason commercial vision teams typically fine-tune the released SAM weights (which are Apache 2.0) rather than retrain from scratch on SA-1B [1] [3].
SAM 2: extending segmentation to video
On July 29, 2024, Meta released SAM 2: Segment Anything in Images and Videos, the second-generation foundation model in the family [4] [5]. SAM 2 is the first unified model that segments objects across images and videos with the same architecture, treating an image as a single-frame video.
The SAM 2 paper, "SAM 2: Segment Anything in Images and Videos" (arXiv:2408.00714), was authored by Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Raedle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollar, and Christoph Feichtenhofer [5].
Architecture changes
SAM 2 keeps the prompt encoder, mask decoder, and image-level encoding ideas from SAM 1, but introduces three changes [5]:
- Hierarchical image encoder (Hiera). The ViT encoder is replaced with a hierarchical Hiera backbone (Ryali et al., 2023) that produces multiscale features at low cost. Hiera removes the heavy vision-specific add-ons (cross-shaped windows, relative position biases) that earlier hierarchical ViTs relied on, while keeping the multiscale structure that segmentation and detection benefit from.
- Memory encoder, memory bank, and memory attention. A streaming memory module stores embeddings of past frames; the current frame attends to these memories. This lets the model track an object across frames even when it is briefly occluded or leaves the view.
- Streaming inference. Frames are consumed one at a time, so the model can run on long videos without holding the full clip in memory.
When applied to a single static image, the memory module is empty and SAM 2 behaves like a stronger SAM. According to Meta, SAM 2 is roughly 6 times faster than SAM 1 on image segmentation while also being more accurate, and it produces better video object segmentation than prior methods using about 3 times fewer interactions [4] [5]. Meta reports approximately 44 frames per second on a single H100 GPU for image segmentation, and similar throughput on video with the memory module active [5].
Model sizes
SAM 2 ships in four sizes that match Hiera variants: Tiny, Small, Base+, and Large. The Large checkpoint has roughly 224 million parameters total, of which the Hiera backbone is by far the largest component. This is notably smaller than SAM ViT-H, yet it still beats SAM ViT-H on the image-only zero-shot benchmarks reported in the SAM 2 paper [5].
| Variant | Backbone | Total parameters | Notes |
|---|---|---|---|
| SAM 2 Tiny | Hiera-T | ~38M | Designed for edge or browser use |
| SAM 2 Small | Hiera-S | ~46M | Default for many demos |
| SAM 2 Base+ | Hiera-B+ | ~80M | Quality and speed trade-off |
| SAM 2 Large | Hiera-L | ~224M | Best accuracy of the family |
The SA-V dataset
SAM 2 is trained on a new video dataset called Segment Anything Video (SA-V). The released SA-V split contains roughly 51,000 videos and around 643,000 spatio-temporal masks ("masklets"), covering whole objects, parts, and challenging occlusions. Of those, about 191,000 masklets were created through SAM 2-assisted manual annotation and around 452,000 were generated automatically by SAM 2 and then verified by humans. Videos were collected from contributors in 47 countries, and Meta states SA-V is roughly 53 times larger than the largest prior video object segmentation dataset [5].
SA-V is published under the CC BY 4.0 license, which is significantly more permissive than the SA-1B research-only license. This change reflects both updated thinking inside Meta and the broader trend of releasing datasets under permissive open terms when consent and privacy review allow it [5].
SAM 2.1
On September 29, 2024, Meta released SAM 2.1, an updated set of checkpoints alongside training code and a developer suite. The 2.1 update improves handling of small and visually similar objects through new data augmentations, and improves occlusion robustness by training on longer video sequences [6]. SAM 2 and SAM 2.1 are distributed under Apache 2.0, and the SA-V dataset is released under CC BY 4.0 [5].
SAM 3: segment anything with concepts
On November 19, 2025, Meta announced SAM 3 and SAM 3D, expanding the family beyond click and box prompts into open-vocabulary concept segmentation and 3D reconstruction [7] [8].
Promptable concept segmentation
SAM 3 introduces a new task called Promptable Concept Segmentation (PCS). Given a short noun phrase (such as "yellow school bus"), an image exemplar (a cropped reference object), or a combination of both, SAM 3 returns segmentation masks and unique identities for every matching instance in an image or video. This is a significant change from SAM 1 and SAM 2, which segment one object per prompt. SAM 3 also works with multimodal language models for compositional queries like "people sitting down, but not wearing a red baseball cap" [7] [8].
Architecture and SA-Co dataset
SAM 3 uses a single shared backbone with two heads: an image-level detector and a memory-based video tracker. The model introduces a presence token that decouples recognition from localization, which improves discrimination between similar concepts and boosts detection accuracy. The tracker reuses ideas from SAM 2 so masks remain stable across frames [7] [8]. A new data engine produced Segment Anything with Concepts (SA-Co), a dataset with around 4 million unique concept labels across images and videos, including hard negatives. Meta released a SA-Co benchmark alongside the model and reports that SAM 3 roughly doubles the accuracy of prior systems on PCS in both images and videos [7].
SAM 3D
The November 2025 release also introduced SAM 3D, open-source models for 3D object and human reconstruction from a single image. It ships in two variants: SAM 3D Objects for everyday objects and scenes, and SAM 3D Body for 3D human shape and pose. Meta reports SAM 3D Objects significantly outperforms prior single-image 3D methods on standard benchmarks [8].
Consumer applications
Meta has shipped SAM 3 capabilities in consumer products: video effects on specific people or objects in Edits, Instagram's video-creation app; generation experiences in Vibes on the Meta AI app; and a "View in Room" feature on Facebook Marketplace that uses SAM 3D to visualize listed furniture in a buyer's home [8].
How do the SAM versions differ?
| Model | Release | Modalities | Prompt types | Training data | Headline number |
|---|---|---|---|---|---|
| SAM 1 | April 2023 | Images | Points, boxes, masks | SA-1B (11M images, 1.1B masks) | Up to 636M params (ViT-H) |
| SAM 2 | July 2024 | Images and video | Points, boxes, masks | SA-V (~51k videos, ~643k masklets) | 6x faster on images than SAM 1 |
| SAM 2.1 | September 2024 | Images and video | Points, boxes, masks | SA-V plus augmentations | Improved on small/occluded objects |
| SAM 3 | November 2025 | Images and video | Text phrases, exemplars, points, boxes | SA-Co (~4M unique concepts) | ~2x prior accuracy on PCS |
| SAM 3D | November 2025 | Single-image to 3D | Click or box | Internal 3D datasets | New SOTA on single-image 3D |
Major variants and follow-ups
Within the first year of SAM's release, dozens of follow-up projects retrained, distilled, or extended the model. The most influential are summarized below.
| Project | Authors | Year | Focus | One-line description |
|---|---|---|---|---|
| HQ-SAM | Ke, Ye, et al. (ETH Zurich) | 2023 | Boundary quality | Adds a high-quality output token to SAM; trained on 44k carefully labeled masks [9] |
| MobileSAM | Zhang et al. (Kyung Hee University) | 2023 | Edge deployment | Distills SAM's ViT-H image encoder into a 5M parameter Tiny-ViT [10] |
| FastSAM | Zhao et al. (CASIA) | 2023 | Speed | Replaces the SAM pipeline with a YOLOv8-seg backbone; roughly 50x faster on ViT-H tasks [11] |
| EfficientSAM | Xiong, Varadarajan, et al. (Meta) | CVPR 2024 | Distillation | SAM-trained image encoder distilled into a lightweight ViT using a Masked Image Pretraining (SAMI) objective [12] |
| Grounded SAM | Liu et al. (IDEA-Research) | 2024 | Open-vocabulary | Pipes Grounding DINO text-to-box detections into SAM for text-prompted segmentation [13] |
| MedSAM | Ma et al. (University of Toronto) | Nature Communications 2024 | Medical imaging | SAM fine-tuned on over one million medical image-mask pairs covering CT, MRI, X-ray, pathology and more [14] |
| SAM-Med2D / SAM-Med3D | Cheng et al. (Shanghai AI Lab) | 2023, 2024 | Medical 2D and 3D | Large-scale fine-tunes on hundreds of medical datasets, including 3D volumetric extensions [15] |
| SEEM | Zou et al. (Microsoft) | NeurIPS 2023 | Unified vision prompts | "Segment Everything Everywhere" with text, points, scribbles, and referring masks [16] |
| PerSAM | Zhang et al. (CUHK MMLab) | 2023 | Personalization | One-shot personalization: give SAM a single image of a specific dog and it segments that dog across new images [17] |
| SAM-PT | Rajic et al. (ETH Zurich) | 2023 | Video tracking | Combines SAM with point trackers like CoTracker for promptable video object segmentation before SAM 2 existed [18] |
| Track Anything | Yang et al. (SUSTech) | 2023 | Video editing | Mask propagation tool built on SAM and XMem for one-click video segmentation [19] |
| Inpaint Anything | Yu et al. (USTC and Tencent ARC) | 2023 | Editing pipeline | SAM masks fed into Stable Diffusion / LaMa for click-driven object removal and replacement [20] |
| Semantic-SAM | Li et al. (HKU and Microsoft) | 2023 | Granularity | Single model that produces semantic labels and masks across multiple granularity levels [21] |
HQ-SAM
HQ-SAM (Ke et al., NeurIPS 2023) targets the most common complaint about SAM 1: that the boundaries of returned masks are sometimes coarse, especially around hair, fur, thin grass, and other fine structures. The authors freeze SAM's image encoder, prompt encoder, and most of the mask decoder, and add a single new "high-quality output token" alongside a small upsampling branch that fuses early and late encoder features. They fine-tune only the new components on a small but very precisely annotated set of 44,320 masks. The result outperforms SAM on a suite of boundary-quality benchmarks while preserving SAM's prompting interface [9].
MobileSAM and FastSAM
MobileSAM (Zhang et al., 2023) addresses cost. The original ViT-H image encoder is over 600 million parameters and was not designed for phones or browser tabs without a GPU. MobileSAM distills the image encoder into a Tiny-ViT of approximately 5 million parameters by matching encoder outputs, then keeps SAM's original prompt encoder and mask decoder. It runs about 100 times faster on the encoding step while staying close to SAM on standard benchmarks [10].
FastSAM (Zhao et al., 2023) takes a different route. Instead of distilling SAM, the authors retrain a YOLOv8-seg model on a 2 percent subset of SA-1B, then provide a thin prompting interface on top. The architecture is convolutional rather than transformer-based, which makes it roughly 50 times faster than SAM ViT-H. Quality on fine structures lags behind SAM but is adequate for interactive editing or coarse segmentation [11].
EfficientSAM
EfficientSAM (Xiong, Varadarajan et al., CVPR 2024) was produced by Meta itself. The team introduced a self-supervised pretraining recipe called SAMI (SAM-leveraged Masked Image pretraining), in which the SAM ViT-H encoder acts as a teacher producing features that a small student encoder learns to reconstruct from masked input patches. After SAMI pretraining, the student is fine-tuned on SA-1B with the SAM mask decoder attached. EfficientSAM achieves close to SAM ViT-H quality with a fraction of the parameters and is faster than MobileSAM at similar quality [12].
Grounded SAM and the text-prompt ecosystem
Grounded SAM (Liu et al., 2024) combines Grounding DINO, an open-vocabulary object detector, with SAM. The pipeline is simple: a user types a noun phrase, Grounding DINO returns boxes for matching instances, and those boxes become SAM prompts. The result is open-vocabulary instance segmentation that works without retraining, and it became one of the most popular SAM derivatives on GitHub. IDEA-Research, which built Grounding DINO, maintains the integration and has shipped extensions for video, 3D, and human pose [13].
A related line of work feeds CLIP or other vision-language models into SAM in various ways. The text encoder slot in SAM's prompt encoder is exactly the place these systems plug into.
MedSAM and medical fine-tunes
MedSAM (Ma et al., 2024, Nature Communications) is the most cited medical adaptation of SAM. The authors curated approximately 1.5 million image-mask pairs from over 30 public medical datasets covering CT, MRI, ultrasound, fluoroscopy, endoscopy, pathology, mammography, and dermoscopy. They fine-tuned SAM's mask decoder on this corpus while keeping the image encoder frozen for the most part. MedSAM outperforms task-specific specialist models on many out-of-distribution medical tasks and works with bounding-box prompts directly from clinicians [14].
SAM-Med2D and SAM-Med3D (Cheng et al., 2023 and 2024) take a different approach, training on even larger curated medical corpora and explicitly extending the architecture to 3D volumes via a 3D image encoder and 3D prompts. SAM-Med3D is one of the first 3D foundation models for medical segmentation that handles full CT and MRI volumes natively [15].
Other notable medical follow-ups include Polyp-SAM, AutoSAM (auto-prompting for pathology), and SAMed (LoRA fine-tuning of SAM on small medical datasets). All of them treat SAM as a strong prior and adapt only what is necessary.
SEEM, PerSAM, SAM-PT, and other research
SEEM (Zou et al., NeurIPS 2023), short for "Segment Everything Everywhere All at Once," predates SAM 2 by about a year and offers a different unification: a single model that accepts text, click, box, scribble, and referring-image prompts, returning both masks and labels. It was developed at Microsoft Research [16].
PerSAM (Zhang et al., 2023) addresses one-shot personalization. Given a single example image of a specific dog, a specific mug, or a specific person, PerSAM can locate and segment that exact instance in unseen images. The trick is to extract a small set of class-agnostic features from the example, then use them as a prompt embedding for SAM. A LoRA-tuned variant called PerSAM-F closes much of the remaining quality gap to fully supervised models [17].
SAM-PT (Rajic et al., 2023) demonstrated promptable video segmentation by combining SAM with point trackers such as CoTracker. The pipeline tracks a few seed points selected on the first frame and feeds them as prompts to SAM in each subsequent frame. SAM-PT was effectively a working prototype of what SAM 2 later did natively [18].
Variant timeline
| Date | Release | Type |
|---|---|---|
| April 2023 | SAM (Meta) | Foundation model |
| April 2023 | SEEM (Microsoft) | Unified prompt segmentation |
| April 2023 | Grounded SAM v0 (IDEA-Research) | Text-prompt pipeline |
| May 2023 | Inpaint Anything | Editing pipeline |
| June 2023 | FastSAM | Lightweight reimplementation |
| June 2023 | MobileSAM | Distilled encoder |
| July 2023 | HQ-SAM | Boundary quality |
| August 2023 | SAM-PT | Video tracking |
| August 2023 | SAM-Med2D | Medical 2D |
| October 2023 | Semantic-SAM | Multi-granularity |
| December 2023 | EfficientSAM (Meta) | Distillation |
| January 2024 | MedSAM (Nature Communications) | Medical foundation |
| April 2024 | SAM-Med3D | Medical 3D |
| July 2024 | SAM 2 (Meta) | Video segmentation |
| September 2024 | SAM 2.1 (Meta) | Update |
| November 2025 | SAM 3 and SAM 3D (Meta) | Concept and 3D |
What is SAM used for?
SAM's prompt-and-mask interface is general enough that it has been picked up across many fields. The most active areas are listed below.
Medical imaging
Medical segmentation is the single largest application domain for SAM. Public benchmarks for tumor segmentation, organ segmentation, lesion detection, cell counting, and surgical scene understanding have all seen SAM-based entries within months of release. The main barrier is that medical imagery is far out-of-distribution from SA-1B (grayscale, often 3D, lower contrast, organ-shaped rather than object-shaped). MedSAM, SAM-Med, and similar systems address this by fine-tuning. MedSAM in particular has been adopted by several hospital research groups as a baseline annotation tool, and a 2024 Nature Communications publication makes it citeable in clinical research [14] [15].
Satellite and earth observation
SAM is widely used to extract building footprints, roads, agricultural plots, deforestation areas, and post-disaster damage from satellite and aerial imagery without per-region retraining. Reza et al. (2023) and follow-up work showed that SAM with grid prompts can produce reasonable instance masks for buildings in arbitrary geographies, which is hard for closed-vocabulary detectors trained on city-specific data. Tooling such as samgeo and the geospatial extension in QGIS exposes SAM through a familiar GIS interface.
Robotics
In robotics, SAM is used as a perception primitive. Grasping pipelines query SAM with point prompts on RGB frames to extract clean object masks, which then feed into grasp planners or 6D pose estimators. Mobile manipulators use SAM masks to build foreground segmentations of objects in cluttered environments. Because the pipeline is prompt-driven, the same robot system can be repointed at new objects without retraining a detector. Newer robotics stacks combine SAM 2's video memory with point trackers to follow objects across long manipulation episodes.
Content creation and editing
The most user-visible applications of SAM are creative. SAM and SAM 2 power one-click object selection in editing tools and online demos. Photoshop's Object Selection tool incorporates SAM-style segmentation, and a number of generative image apps use SAM to define masks for inpainting and outpainting. Inpaint Anything (Yu et al., 2023) was the first popular pipeline that chained SAM with Stable Diffusion and LaMa to support click-driven object removal and replacement [20]. Meta now ships SAM-derived effects directly in Instagram Edits, the Vibes app, and Facebook Marketplace (using SAM 3D) [8].
Annotation tools and data labeling
SAM rapidly became a default backend for annotation platforms. CVAT, Label Studio, V7, Encord, Supervisely, and Roboflow all integrate SAM (and now SAM 2) as an interactive labeler. The pattern is the same in each tool: a user clicks an object, SAM proposes a mask, the user accepts or refines. This has compressed segmentation labeling time by roughly an order of magnitude in many production pipelines.
Scientific imaging
Microscopy is another natural fit. Cell biology groups have fine-tuned SAM on cellular imagery (Cellpose-SAM, Micro-SAM) and use it to segment cells, organelles, and tissue compartments across modalities. SAM has also been used on electron microscopy, X-ray crystallography images, and astronomical surveys.
3D and AR
Mask outputs from SAM are used as priors for 3D reconstruction, neural radiance field training (SA3D, SAM-3D family), and AR object placement. SAM 3D from Meta's November 2025 release brings this into the SAM family natively [8].
Video editing
Before SAM 2 existed, video pipelines combined SAM with mask propagators such as XMem or with point trackers (Track Anything, SAM-PT). With SAM 2's streaming memory, much of this can be done in a single model. Online tools now let a user click an object in the first frame of a clip and get a tracked mask across the rest, which is the core building block of effects like background blur, object removal, and rotoscoping.
Benchmarks and zero-shot results
The original SAM paper introduced a 23-dataset evaluation suite covering domains the model never saw during training. These include BBBC038v1 (cell microscopy), DOORS (drone scenes), DRAM (paintings), Hypersim (synthetic indoor scenes), iShape (shapes), LVIS, NDD20 (underwater dolphins), Plittersdorf (camera trap), PIDRay (security X-ray), TimberSeg (forestry), VISOR (egocentric), and several others. SAM was evaluated in two modes: single-point prompting and oracle ground-truth box prompting. In both modes, SAM matched or exceeded fully supervised baselines on the majority of datasets [1].
For video, SAM 2 reports results on DAVIS 2017, MOSE, YouTube-VOS 2019, and SA-V benchmark splits, with state-of-the-art numbers on each as of release. SAM 2 also beats SAM 1 on standard image benchmarks despite using a smaller backbone [5].
Indicative numbers from the SAM 2 paper
| Benchmark | Task | SAM ViT-H | SAM 2 (Hiera-L) |
|---|---|---|---|
| LVIS | Zero-shot instance segmentation (mIoU from 1-click) | strong | better |
| 23-dataset suite | Zero-shot single-point mIoU | strong | better |
| DAVIS 2017 | Semi-supervised video object segmentation (J&F) | not applicable | state-of-the-art |
| MOSE | Video object segmentation under occlusion | not applicable | state-of-the-art |
| SA-V test | Promptable video object segmentation | not applicable | state-of-the-art |
(The SAM 2 paper [5] reports exact metric numbers; the table above is a qualitative summary, since headline numbers shift with the specific checkpoint and prompting protocol.)
Reception and impact
SAM became one of the most cited computer vision papers of 2023. By early 2025 it had accumulated more than 10,000 citations on Google Scholar across model, dataset, and follow-up uses, and SAM 2 was already heading in the same direction. The Apache 2.0 weights, the open code, the live demo, and the SA-1B dataset together set a template that subsequent vision foundation model releases (DINOv2, V-JEPA, OWL-ViT, OpenSeeD) followed [1] [3] [22].
The industry response was broad. Annotation companies retooled their products around SAM within weeks. Cloud providers added SAM endpoints to their managed vision services. Generative AI tools used SAM masks as the bridge between text-to-image diffusion models and editing workflows. Medical imaging groups used MedSAM as a baseline annotator. Inside Meta, SAM and SAM 2 were folded into Instagram, Facebook, and the Meta AI app.
SAM is also widely treated as a case study in data-centric AI. The data engine (model assists annotation, annotations train better model, better model annotates more) was a more deliberate and more documented version of bootstrapping than prior work. Subsequent projects in robotics (RT-X, Open X-Embodiment), autonomous driving, and medical imaging cite it as the reference for building large-scale promptable datasets.
ICCV 2023 awarded SAM a Best Paper Honorable Mention [1].
Limitations
Despite the success, SAM and its successors have well-known limits.
- No class labels. SAM produces masks, not labels. To know what is in a mask, a downstream classifier or vision-language model is needed. SAM 3's PCS partly addresses this for video and image text prompts, but SAM 1 and SAM 2 by themselves do not label anything.
- Boundary quality on fine structure. Hair, fur, fine grass, lace, mesh, and other fine textures often produce coarse SAM masks. HQ-SAM and dedicated boundary-refinement networks help, but the underlying ViT and SAM mask decoder were not optimized for sub-pixel detail.
- Out-of-distribution medical and scientific imagery. SAM's training set is natural photographs. Direct application to CT, MRI, electron microscopy, or astronomical imagery often gives poor results without fine-tuning. MedSAM and SAM-Med exist precisely because of this gap.
- Failure on very small or very thin objects. The 1024 by 1024 input resolution means that tiny objects (a few pixels across in the original image) can be lost entirely.
- Video drift over long sequences. SAM 2's memory is finite. Over very long videos with fast motion or repeated occlusions, the tracked mask can drift onto a similar but wrong object. SAM 2.1 reduced this with longer training sequences but did not eliminate it.
- Compute cost. Even with the cached encoder design, the ViT-H image encoder is heavy and limits SAM's use on mobile and embedded hardware. The MobileSAM, FastSAM, and EfficientSAM follow-ups exist for this reason.
- Dataset bias. Although SA-1B has broader geographic coverage than most prior vision datasets, the images still come from a single licensed source and skew toward photographic subjects rather than industrial, medical, or microscopic content.
- No native part hierarchy. SAM does produce three masks per prompt that correspond loosely to whole, part, and subpart, but it does not produce a clean object-part-subpart tree. Semantic-SAM and other follow-ups attempted to address this more directly [21].
Is SAM open source? Licensing
Licensing terms across the SAM family are summarized below.
| Asset | License | Notes |
|---|---|---|
| SAM 1 model weights | Apache 2.0 | Commercial use allowed |
| SAM 1 code | Apache 2.0 | facebookresearch/segment-anything |
| SA-1B dataset | Custom research license | Non-commercial; redistribution restricted; re-identification prohibited |
| SAM 2 model weights | Apache 2.0 | Commercial use allowed |
| SAM 2 code | Apache 2.0 | facebookresearch/sam2 |
| SA-V dataset | CC BY 4.0 | More permissive than SA-1B |
| SAM 2.1 weights and code | Apache 2.0 | facebookresearch/sam2 |
| SAM 3 weights and code | Custom (Meta SAM 3 license) | See repository for restrictions |
| SAM 3D weights and code | Open release | See repository for terms |
The split between very permissive model weights and more restrictive dataset terms is intentional. Meta wanted the models themselves to be broadly usable in commercial products while keeping the original image set under research-only terms because of privacy and licensing constraints on the third-party photo source [1] [3] [5].
FAQs and additional information
SAM 1 predicts object masks only and does not generate labels. It supports images or individual frames extracted from videos, but not videos directly. SAM 2 added native video support, and SAM 3 added text-prompted multi-instance segmentation. Source code and checkpoints for all SAM versions are on the Meta AI Research GitHub organization [3] [5] [7].
Can SAM be retrained on my own data? Yes. The published Apache 2.0 weights are a good starting checkpoint, and several open codebases (segment-anything, sam2, SAMed, MedSAM training scripts) demonstrate full fine-tuning, LoRA fine-tuning, and decoder-only fine-tuning.
Does SAM work on grayscale or single-channel images? It can, but it was trained on RGB. The typical recipe is to replicate the single channel three times so the input has three channels. Quality is usually adequate for natural-looking grayscale images and noticeably worse on medical scans, where MedSAM or SAM-Med is preferable.
How does SAM compare to traditional U-Net based segmentation? SAM is interactive and zero-shot, while a U-Net trained on a specific dataset is supervised and typically scoped to that dataset's classes. On in-distribution data with abundant labels, a well-tuned U-Net can still beat SAM, but it does not generalize. SAM is the better choice when the segmentation classes are open-ended or when there is little labeled data.
Why does SAM return three masks? Because a single prompt is often ambiguous. A click on a cup may refer to the cup, the rim, or the handle. Returning three candidates lets a downstream system (or a human) pick the right granularity.
See also
- Vision Transformer
- Foundation model
- Computer vision
- Meta AI
- CLIP
- Grounding DINO
- Stable Diffusion
- Image segmentation
- Object detection
- Training data
Recent developments (2026)
SAM 3.1. On March 27, 2026, Meta released SAM 3.1, described as a drop-in replacement for SAM 3 focused on faster real-time video tracking. The main change is object multiplexing: instead of running a separate tracking path for every object, SAM 3.1 extracts shared frame features once into a shared-memory buffer and processes all objects jointly on top of that representation, tracking up to 16 objects in a single forward pass. Meta calls the joint pass a global-reasoning approach and reports that it both removes redundant computation and improves accuracy in crowded scenes. For videos with a moderate number of objects, throughput on a single NVIDIA H100 GPU roughly doubles from 16 to 32 frames per second, and the speedup grows with object count, reaching about 7 to 8 times faster than SAM 3 when tracking around 128 objects. SAM 3.1 checkpoints are published on Hugging Face under facebook/sam3.1, and the model is reachable through Meta's Segment Anything Playground demo [25] [26].
SAM 3 at ICLR 2026. The SAM 3 paper "Segment Anything with Concepts" was accepted to ICLR 2026 and presented as a poster on April 25, 2026; the arXiv preprint was revised to version 2 on March 28, 2026, alongside the SAM 3.1 release [25] [27]. The released SAM 3 model has about 848 million parameters, with its image-level detector and memory-based video tracker sharing a single vision encoder [26].
SAM 3D Body paper. A dedicated paper for the human-reconstruction half of the November 2025 SAM 3D release, "SAM 3D Body: Robust Full-Body Human Mesh Recovery," was posted to arXiv on February 17, 2026. It frames full-body 3D mesh recovery from a single image as a promptable task that can take 2D keypoints and masks as auxiliary prompts, and it introduces a new parametric body representation called the Momentum Human Rig (MHR) that covers body, hands, and feet. The model and the MHR representation were open-sourced [28].
References
- Kirillov, Alexander; Mintun, Eric; Ravi, Nikhila; Mao, Hanzi; Rolland, Chloe; Gustafson, Laura; Xiao, Tete; Whitehead, Spencer; Berg, Alexander C.; Lo, Wan-Yen; Dollar, Piotr; Girshick, Ross. "Segment Anything." arXiv:2304.02643, April 5, 2023. https://arxiv.org/abs/2304.02643 ↩
- Meta AI. "Introducing Segment Anything: Working toward the first foundation model for image segmentation." Meta AI Blog, April 5, 2023. https://ai.meta.com/blog/segment-anything-foundation-model-image-segmentation/ ↩
- Meta AI Research. "facebookresearch/segment-anything" GitHub repository. https://github.com/facebookresearch/segment-anything ↩
- Meta AI. "Introducing Meta Segment Anything Model 2 (SAM 2)." Meta AI Research, July 29, 2024. https://ai.meta.com/research/sam2/ ↩
- Ravi, Nikhila; Gabeur, Valentin; et al. "SAM 2: Segment Anything in Images and Videos." arXiv:2408.00714, July 2024. https://arxiv.org/abs/2408.00714 ↩
- Meta AI. "SAM 2.1 Developer Suite" release notes (facebookresearch/sam2 GitHub), September 29, 2024. https://github.com/facebookresearch/sam2 ↩
- Meta AI Research. "SAM 3: Segment Anything with Concepts." arXiv:2511.16719, November 19, 2025. https://arxiv.org/abs/2511.16719 ↩
- Meta. "New Segment Anything Models Make it Easier to Detect Objects and Create 3D Reconstructions." Meta Newsroom, November 19, 2025. https://about.fb.com/news/2025/11/new-sam-models-detect-objects-create-3d-reconstructions/ ↩
- Ke, Lei; Ye, Mingqiao; Danelljan, Martin; Liu, Yifan; Tai, Yu-Wing; Tang, Chi-Keung; Yu, Fisher. "Segment Anything in High Quality." arXiv:2306.01567 / NeurIPS 2023. https://arxiv.org/abs/2306.01567 ↩
- Zhang, Chaoning; Han, Dongshen; Qiao, Yu; Kim, Jung Uk; Bae, Sung-Ho; Lee, Seungkyu; Hong, Choong Seon. "Faster Segment Anything: Towards Lightweight SAM for Mobile Applications." arXiv:2306.14289, 2023. https://arxiv.org/abs/2306.14289 ↩
- Zhao, Xu; Ding, Wenchao; An, Yongqi; Du, Yinglong; Yu, Tao; Li, Min; Tang, Ming; Wang, Jinqiao. "Fast Segment Anything." arXiv:2306.12156, 2023. https://arxiv.org/abs/2306.12156 ↩
- Xiong, Yunyang; Varadarajan, Bala; Wu, Lemeng; Xiang, Xiaoyu; Xiao, Fanyi; Zhu, Chenchen; Dai, Xiaoliang; Wang, Dilin; Sun, Fei; Iandola, Forrest; Krishnamoorthi, Raghuraman; Chandra, Vikas. "EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything." CVPR 2024. arXiv:2312.00863. https://arxiv.org/abs/2312.00863 ↩
- Ren, Tianhe; Liu, Shilong; Zeng, Ailing; Lin, Jing; Li, Kunchang; Cao, He; Chen, Jiayu; Huang, Xinyu; Chen, Yukang; Yan, Feng; Zeng, Zhaoyang; Zhang, Hao; Li, Feng; Yang, Jie; Li, Hongyang; Jiang, Qing; Zhang, Lei. "Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks." arXiv:2401.14159, IDEA-Research, 2024. https://arxiv.org/abs/2401.14159 ↩
- Ma, Jun; He, Yuting; Li, Feifei; Han, Lin; You, Chenyu; Wang, Bo. "Segment anything in medical images." *Nature Communications* 15, 654 (2024). https://www.nature.com/articles/s41467-024-44824-z ↩
- Cheng, Junlong; Ye, Jin; Deng, Zhongying; Chen, Jianpin; Li, Tianbin; Wang, Haoyu; Su, Yanzhou; Huang, Ziyan; Chen, Jilong; Jiang, Lei; Sun, Hui; He, Junjun; Zhang, Shaoting; Zhu, Min; Qiao, Yu. "SAM-Med2D." arXiv:2308.16184, 2023. https://arxiv.org/abs/2308.16184 ↩
- Zou, Xueyan; Yang, Jianwei; Zhang, Hao; Li, Feng; Li, Linjie; Wang, Jianfeng; Wang, Lijuan; Gao, Jianfeng; Lee, Yong Jae. "Segment Everything Everywhere All at Once." NeurIPS 2023. arXiv:2304.06718. https://arxiv.org/abs/2304.06718 ↩
- Zhang, Renrui; Jiang, Zhengkai; Guo, Ziyu; Yan, Shilin; Pan, Junting; Dong, Hao; Gao, Peng; Li, Hongsheng. "Personalize Segment Anything Model with One Shot." arXiv:2305.03048, 2023. https://arxiv.org/abs/2305.03048 ↩
- Rajic, Frano; Ke, Lei; Tai, Yu-Wing; Tang, Chi-Keung; Danelljan, Martin; Yu, Fisher. "Segment Anything Meets Point Tracking." arXiv:2307.01197, 2023. https://arxiv.org/abs/2307.01197 ↩
- Yang, Jinyu; Gao, Mingqi; Li, Zhe; Gao, Shang; Wang, Fangjing; Zheng, Feng. "Track Anything: Segment Anything Meets Videos." arXiv:2304.11968, 2023. https://arxiv.org/abs/2304.11968 ↩
- Yu, Tao; Feng, Runseng; Feng, Ruoyu; Liu, Jinming; Jin, Xin; Zeng, Wenjun; Chen, Zhibo. "Inpaint Anything: Segment Anything Meets Image Inpainting." arXiv:2304.06790, 2023. https://arxiv.org/abs/2304.06790 ↩
- Li, Feng; Zhang, Hao; Sun, Peize; Zou, Xueyan; Liu, Shilong; Yang, Jianwei; Li, Chunyuan; Zhang, Lei; Gao, Jianfeng. "Semantic-SAM: Segment and Recognize Anything at Any Granularity." arXiv:2307.04767, 2023. https://arxiv.org/abs/2307.04767 ↩
- Wikipedia contributors. "Segment Anything Model." Wikipedia. https://en.wikipedia.org/wiki/Segment_Anything_Model ↩
- He, Kaiming; Chen, Xinlei; Xie, Saining; Li, Yanghao; Dollar, Piotr; Girshick, Ross. "Masked Autoencoders Are Scalable Vision Learners." CVPR 2022. arXiv:2111.06377. https://arxiv.org/abs/2111.06377
- Ryali, Chaitanya; Hu, Yuan-Ting; Bolya, Daniel; Wei, Chen; Fan, Haoqi; Huang, Po-Yao; Aggarwal, Vaibhav; Chowdhury, Arkabandhu; Poursaeed, Omid; Hoffman, Judy; Malik, Jitendra; Li, Yanghao; Feichtenhofer, Christoph. "Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles." ICML 2023. arXiv:2306.00989. https://arxiv.org/abs/2306.00989
- Meta AI. "SAM 3.1: Faster and More Accessible Real-Time Video Detection and Tracking With Multiplexing and Global Reasoning." AI at Meta Blog, March 27, 2026. https://ai.meta.com/blog/segment-anything-model-3/ ↩
- Meta AI Research. "facebookresearch/sam3" GitHub repository (SAM 3 and SAM 3.1 code and checkpoints). https://github.com/facebookresearch/sam3 ↩
- "SAM 3: Segment Anything with Concepts." ICLR 2026 poster, presented April 25, 2026. https://iclr.cc/virtual/2026/poster/10007181 ↩
- Yang, Xitong; Kukreja, Devansh; Pinkus, Don; Sagar, Anushka; Fan, Taosha; Park, Jinhyung; Shin, Soyong; Cao, Jinkun; Liu, Jiawei; Ugrinovic, Nicolas; Feiszli, Matt; Malik, Jitendra; Dollar, Piotr; Kitani, Kris. "SAM 3D Body: Robust Full-Body Human Mesh Recovery." arXiv:2602.15989, February 17, 2026. https://arxiv.org/abs/2602.15989 ↩
Improve this article
Add missing citations, update stale details, or suggest a clearer explanation. Every suggestion is reviewed for sourcing before it goes live.
6 revisions by 1 contributors · full history